





.png)


I’m a new software developer here at HarperDB. So like many of you visiting the blog, I’ve got fresh eyes on this product. Two weeks ago, my sights were set on HarperDB’s newest feature, Custom Functions. My task was to create a plug-and-play REST API template with our Custom Functions. As you read this I hope you’ll feel confident to follow along, and after some practice implement this into your next project!
So what are Custom Functions?
Simply put, Custom Functions (CF) are serverless, highly customizable API endpoints that interact with our HarperDB Core operations, such as “insert”, “search_by_hash”, “update”, and more.
You could define a CF using SQL to return all dog data records where the owner’s name is “Geena Davis” and sort them by the dog’s name. You can create a CF that deletes a dog’s data record using a route parameter and NoSQL. You can also make a CF with validation that saves a dog’s record with required properties. Custom Functions are powered by Fastify and are extremely flexible. To see possibilities, check out their docs on routes.
Here’s a simple CF that gets a data record from the database.

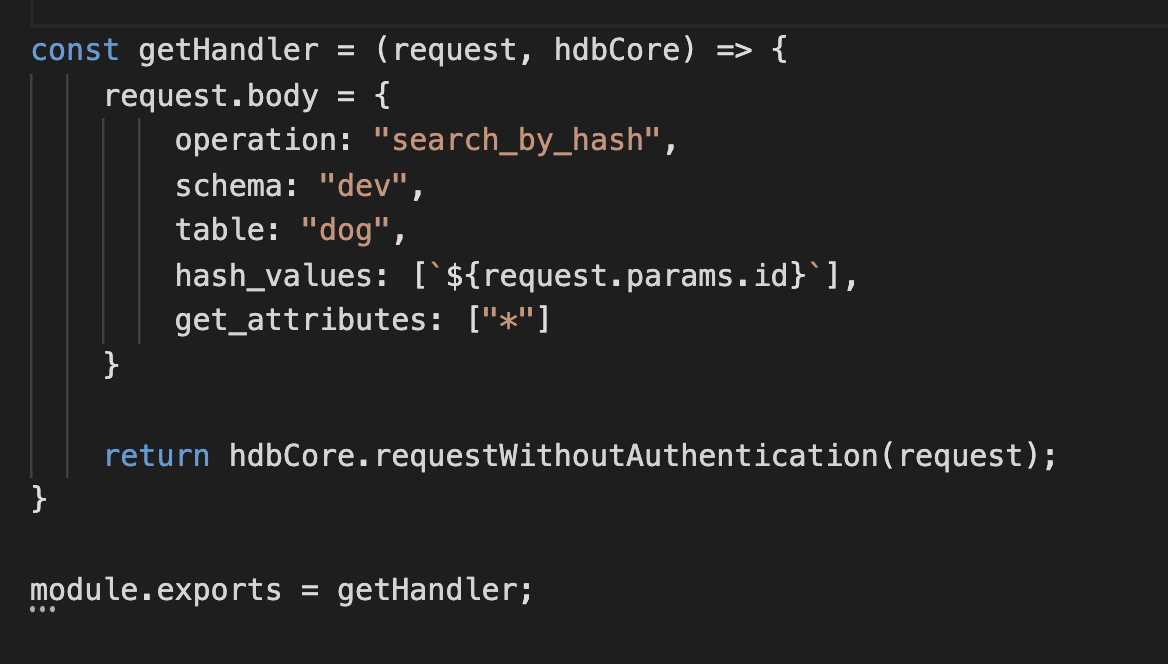

And what about REST?
You’re probably familiar with a REST API. This is an application programming interface that conforms to the constraints of REST architecture and allows for interaction with RESTful web services. They are flexible, scalable, and efficient. RESTful APIs utilize four common HTTP methods: POST, GET, PUT, and DELETE, which correspond with CRUD functionality: create, read, update, and delete.
So why am I combining the two?
A REST API and HarperDB’s Custom Functions combine to make development easy and performance fast. A large aim of HarperDB is to collapse the stack. Traditionally you would need a server running a REST application and a server that runs the database. In this case, you’re only running HarperDB, hence, collapsing the stack.
To the task at hand: build a dynamic REST API with Custom Functions.
I’ll describe what I’ve built first, and then I’ll show how you can use it for your own devices. Instead of going one by one through the routes, I’ll highlight the POST for its simplicity and the PUT for its complexity. All routes can be viewed in the repo.
For this project, the routes have a URL, an HTTP method, and a handler. The handlers have access to hdbCore and I’m using its requestWithoutAuthentication method for simplicity’s sake. In defining routes, I specified a dynamic URL to satisfy a plug-and-play approach. As for HTTP methods, I wanted to make endpoints for standard CRUD so in routes/index.js I built two GET routes (get one and get all), a POST, a PUT, a PATCH, and a DELETE. I included a PUT and a PATCH as they both have their advantages. The PUT updates by replacing an entire record, and PATCH only updates any given values. With that said, the GET, POST, and DELETE aligned beautifully with HarperDB, and the PUT and PATCH required a bit of finessing. In general, the handlers connect the request to hdbCore using a specified HarperDB operation, they utilize route parameters to access the correct data, and they return a response. I’ve chosen to mostly use NoSQL operations, as they work lightning fast with HDB, although you may use SQL as well.
Here’s what the dynamic POST Custom Function looks like:



The POST is pretty simple. It uses the “insert” HDB Core operation, gets schema and table from the request route parameters, and the record sent along with is provided in the request body. An example of what that might look like is provided with the Postman screenshot. The GETs and the DELETE follow the same pattern of simplicity, although use different operations.
And what about the routes that needed more finesse?
In order for the PUT to perform as expected, any given attribute in the request body object will be updated, and any left out attribute will be null. Herein required getting all attributes on the table, done so with an HDB Core operation, “describe_table.” Once that was attained, each attribute of the table was iterated to assign a null value for any attribute that was left out of the request body object. HDB assigned attributes “__createdtime__” and “__updatedtime__” are skipped to maintain their values. And finally, a second HDB Core operation is performed within putHandler.js. This one is “update.” A variable, “put_query_body” has all needed attributes, either assigned through the request body, or made null, and it has the correct unique identifier, the hash_attribute from route params. This is provided to records to perform the update.

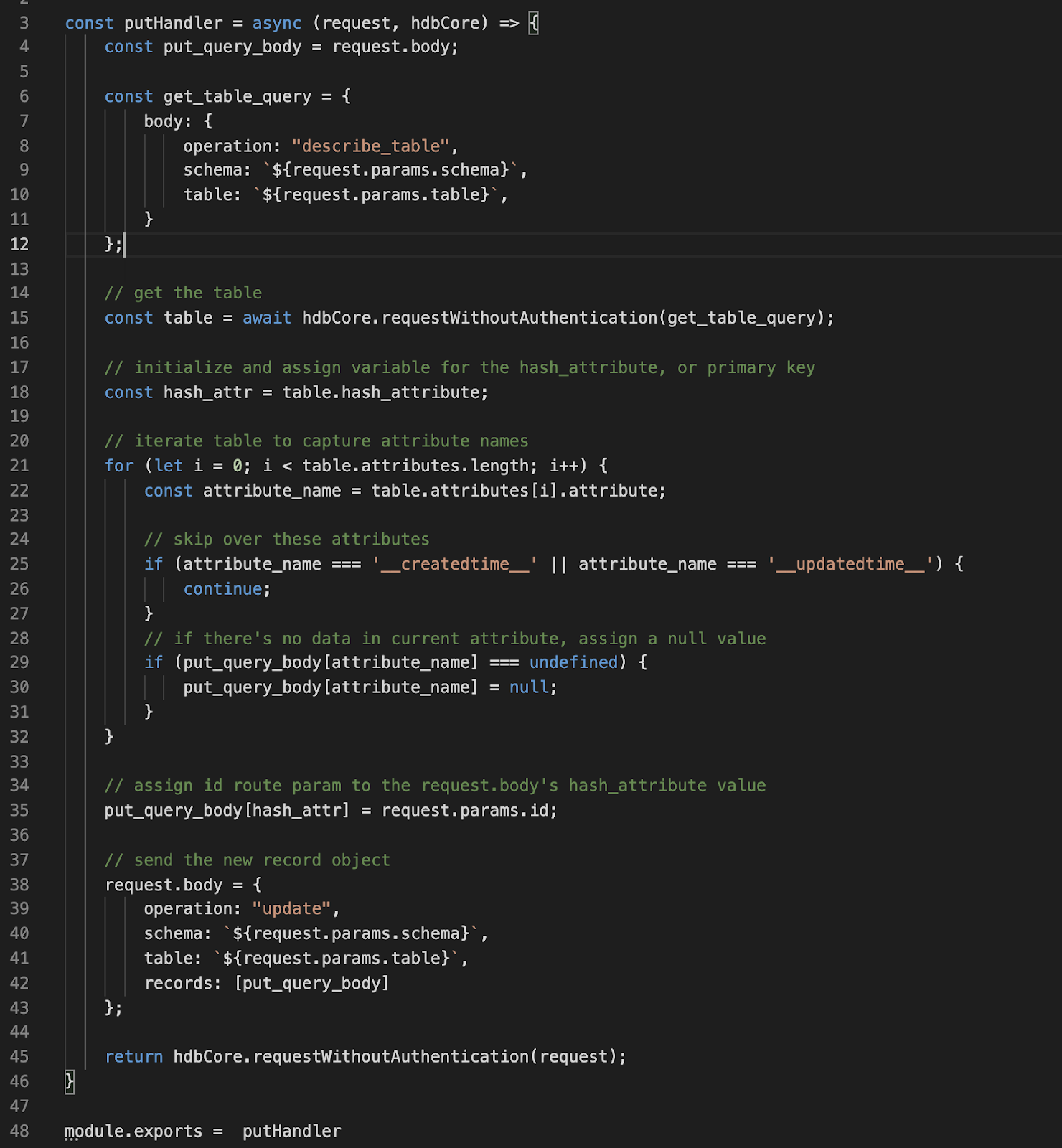
Here’s what that means for your data:
Let’s say the table in question is “dog”, and it has “dog_name”, “age”, “weight_lbs”, and “owner_name” attributes. Below is the record to be updated:

To update the record with PUT, you’d provide this in the request body:

Your record will be completely replaced with the provided values and it will replace weight, and owner_name with null. This is the desired behavior of a PUT request.

A few words on the PATCH...The PATCH is very similar in terms of logic and code. The difference being that there’s no need to nullify any attributes. I still needed to get the attributes from the table with HDB Core to get the hash_attribute and then assign the route param. And finally to send a record object along with the update call to HDB Core. With the PATCH, all that needs updating is what’s provided in the request body. Using the example above, the same beginning record, and the same request body, the PATCH updated record would be:

How can you use this dynamic REST API Custom Functions template?
To use this template, you'll need to be logged in, running HarperDB, have a local instance, and have some data to work with. If you don’t, please follow the steps below. I recommend following this video (from the beginning until about 4:30) to get you through 1-3. I recommend this demo video if you’d like a visual aid for steps 4 and 5 (pick up around 13:00 until about 15:00).
- Sign up/log in here
- Install and run HarperDB
- Create a local instance (in Studio)
- Build some demo data (in Studio)
- Enable Custom Functions (in Studio)
- Clone this Custom Functions template and party! (open in IDE)
At this point, if you’ve been following along you will have gotten some familiarity with HarperDB Studio. It’s super easy to use and is a great tool for working with the core product. From here on, it’s great to open your Custom Functions project in your favorite IDE, like WebStorm. The “custom_functions” folder lives in the “hdb” folder. Any project you create in Custom Functions lives here.
- Test your endpoints with Postman
The repository includes a Postman collection, which will allow you to test the endpoints against your data. As the REST API template was dynamic, so are the URLs in the Postman collection. Here's a link to this project's environment variables. You will likely need to change some values to fit your project. You may also choose to hard-code the route for your needs, (ex: http://localhost:9926/project/schema/table plus any necessary route parameter such as "id".)
Reflection and/or TL;DR
I made a dynamic REST API using HarperDB’s Custom Functions for developers to implement in their projects. The combination of a REST API and HarperDB reduces the number of servers needed, collapsing the stack, making your project just that much faster!

.png)
